📣 聲明
這些演化的經驗是由數個團隊累積起來的故事,會有些複雜,不容易線性的去陳述。為了更好的描述學習點,我會將實際案例做一些調整,並以同一個團隊的視角去敘述,所以下面的案例會與當時的情況有些差異。
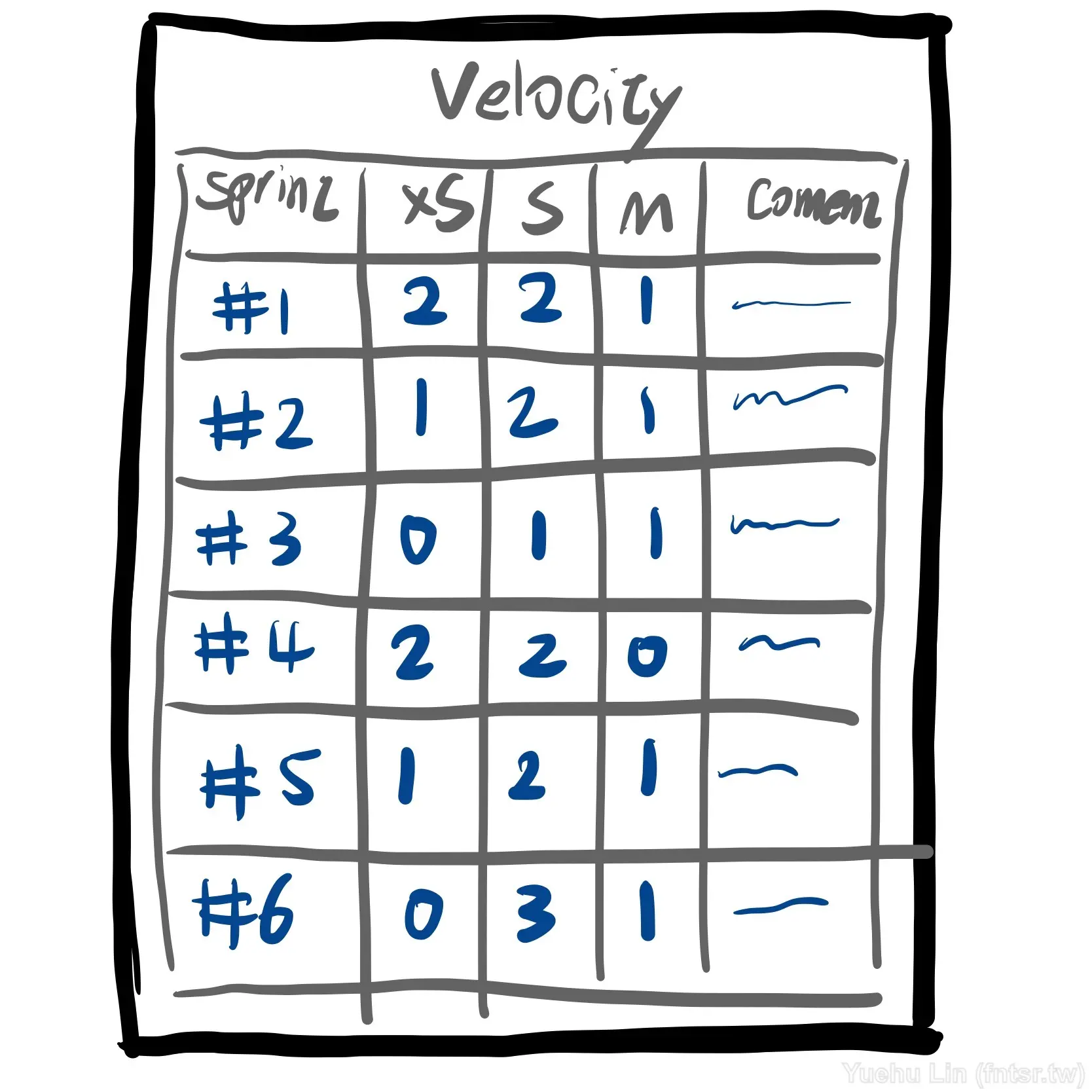
我當初在剛進入 T 社時,首先引入作為實驗的產出物就是 Velocity 的紀錄表,我們當時口語上簡稱「速率表」,而且一開始還很陽春的只是記錄一個 Sprint 拿了幾張S、幾張M,隨著演化,才開始與費氏數列作為綁定,有了數值化、開始畫起了圖表。並以此做為團隊認領的依據、產品負責人自己推估未來消化速度的參考。
發展到後期,就是建立一份 Google Sheets 去記錄每個 Sprint 各項數據,然後做為參考。有了比較正規的累計數據的方式,這是一個好的實踐,讓團隊有足夠的資訊可以參考。
但是,到了後面這樣的做法就開始有點鑽牛角尖了。記錄越細,從交付了多少點數的待辦事項,到原本預期交付多少,落差為多少,甚至到後面開始記錄了這個 Sprint 能用在開發的時間,以及每單位時間的交付比例。的確就是真的把 Velocity 的概念貫徹到底。
下面我就用示意圖與各位談談吧。
就像前面所聊過的,要使用任何指標,最大的困境永遠是在如何持之以恆的搜集。如果一開始就讓團隊去專案管理工具或是任何試算表工具填寫數據,對開發團隊來說就只是多一道行政手續,資訊冰箱只要每多一個步驟,就像是將冰箱門多加一公斤重量一樣。
打開電腦、打開瀏覽器、找到填寫的頁面、編輯頁面、輸入數據,想想看,6 公斤的冰箱門。這還是比較客氣的,筆者甚至認為應該要像費事數列一樣把公斤數加上去才更貼切:「1+2+3+5+8 = 19」,嗯,19 公斤。
所以最一開始要讓步驟縮減到最短,而且成效最直覺化!不要想這一開始就先用數位化工具,直接將要填的數據印成一張 A4 紙吧!讓團隊隨手在 Review 或是 Planning 的一開始記錄下來,甚至一開始先讓 ScrumMaster / Agile Coach 用口頭詢問,直接代填,也是可以。
然後每次預測下一個 Sprint 可以認領多少工作量時,就將這張紙拿給團隊看,漸漸的團隊就會感受到有數據可以參考的好處,而開始買單這樣的實踐方式。
甚至也先不要改變團隊既有的估算方式,持續用 T-Shirt Size,只計算張數就好。當他們買單這樣的實踐方式時,自然就會感到沒有量化的不方便,而自主地提出想要數據化的需求
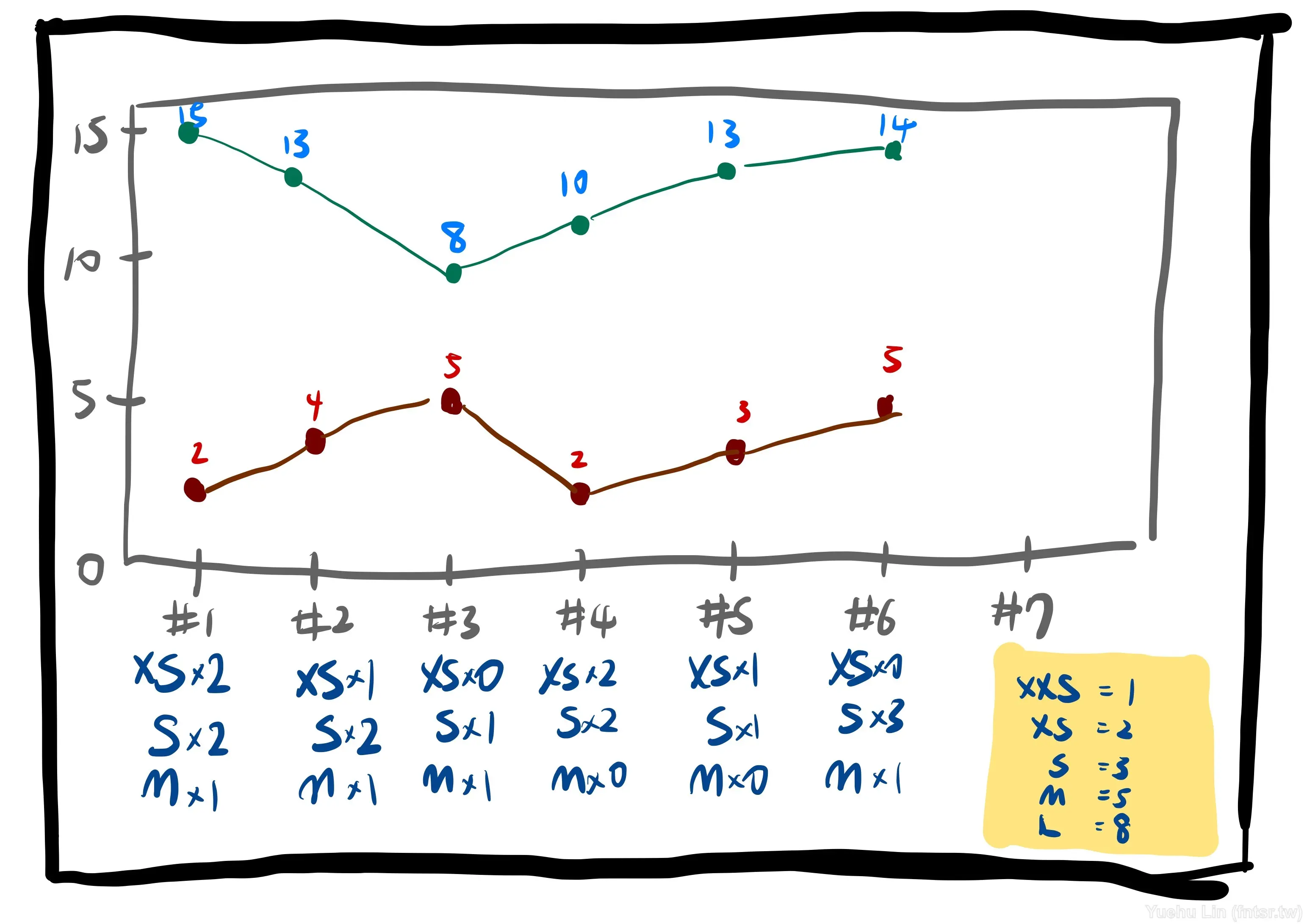
當團隊開始有量化的需求時,這時候筆者提出的解決方案是將 T-Shirt Size 與費式數列(Fibonacci sequence)對映,如上圖右邊便利貼的對照表。一樣是先維持既有習慣,紀錄有 T-Shirt Size 的張數,然後再轉換成費式數列,這樣就有了每週交付量的與未完成量的數據了。有數據、有指標,接下來就可以嘗試圖表化了,於是第一版的圖表就是將這兩個數據畫成折線圖去表示。
現在想想其實用直條圖按比例去繪製可能更好,但當時還在手繪階段,折線圖還是相對容易繪製,所以才會這樣考量與決定的吧!
這時候除了有指標可以預測下一個 Sprint 的交付工作量外,也讓團隊可以回頭檢視進幾個 Sprint 的交付狀況的穩定度,作為 Retrospective 的參考指標。
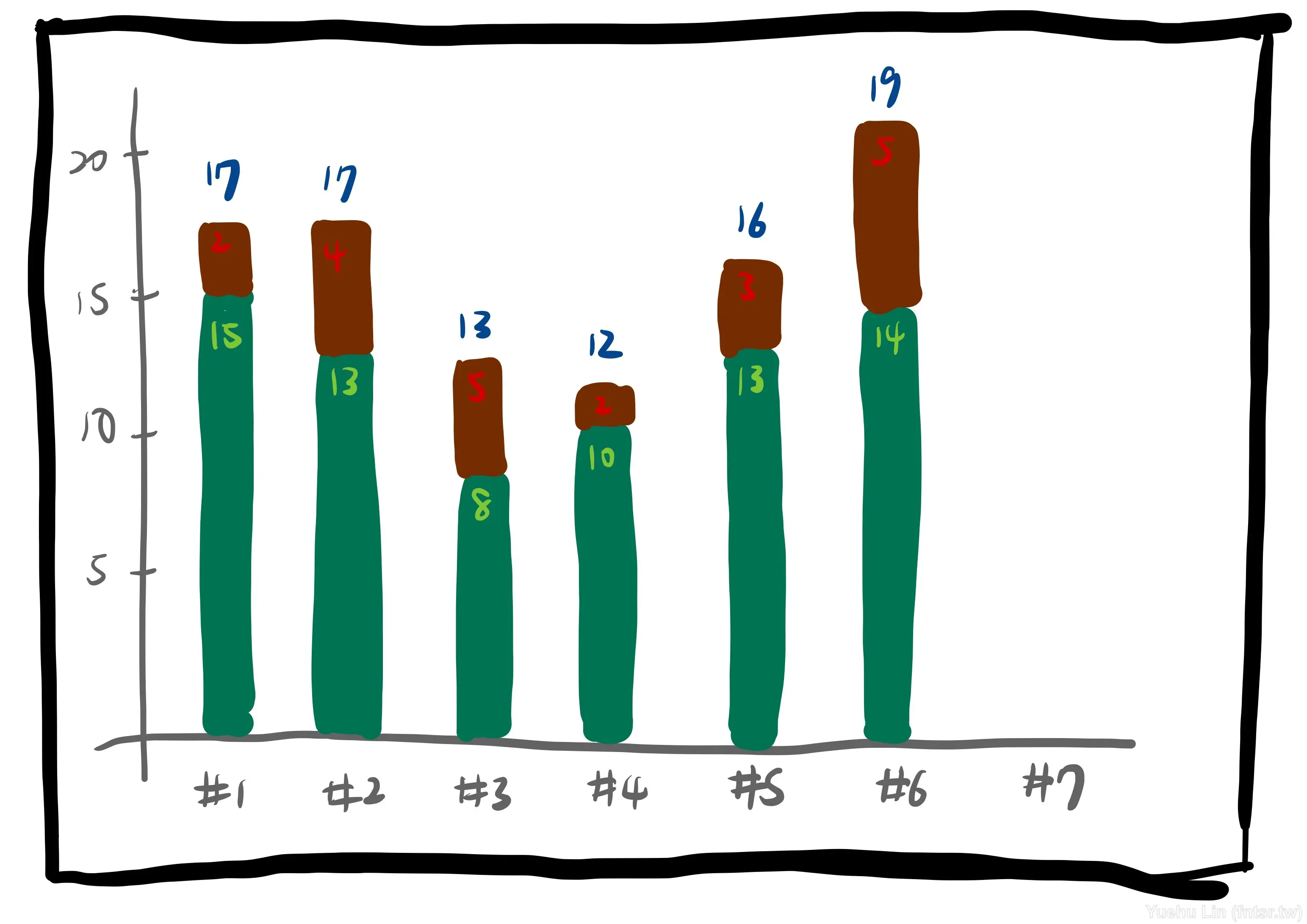
接下來遇到了疫情時期,開啟了在家工作的合作模式,紙本的產出物都不得不數位化。也是利用這個契機,將紙本的 Velocity 紀錄表改成 Google Sheets 的型態。因為不用再花時間繪製,改成用直條圖的方式呈現數據,就可以比較清楚的看到未完成量與交付量。到這邊其實 Velocity 紀錄表其實將未完成量區分成尚未展開以及做到一半的話,其實也就差不多了。
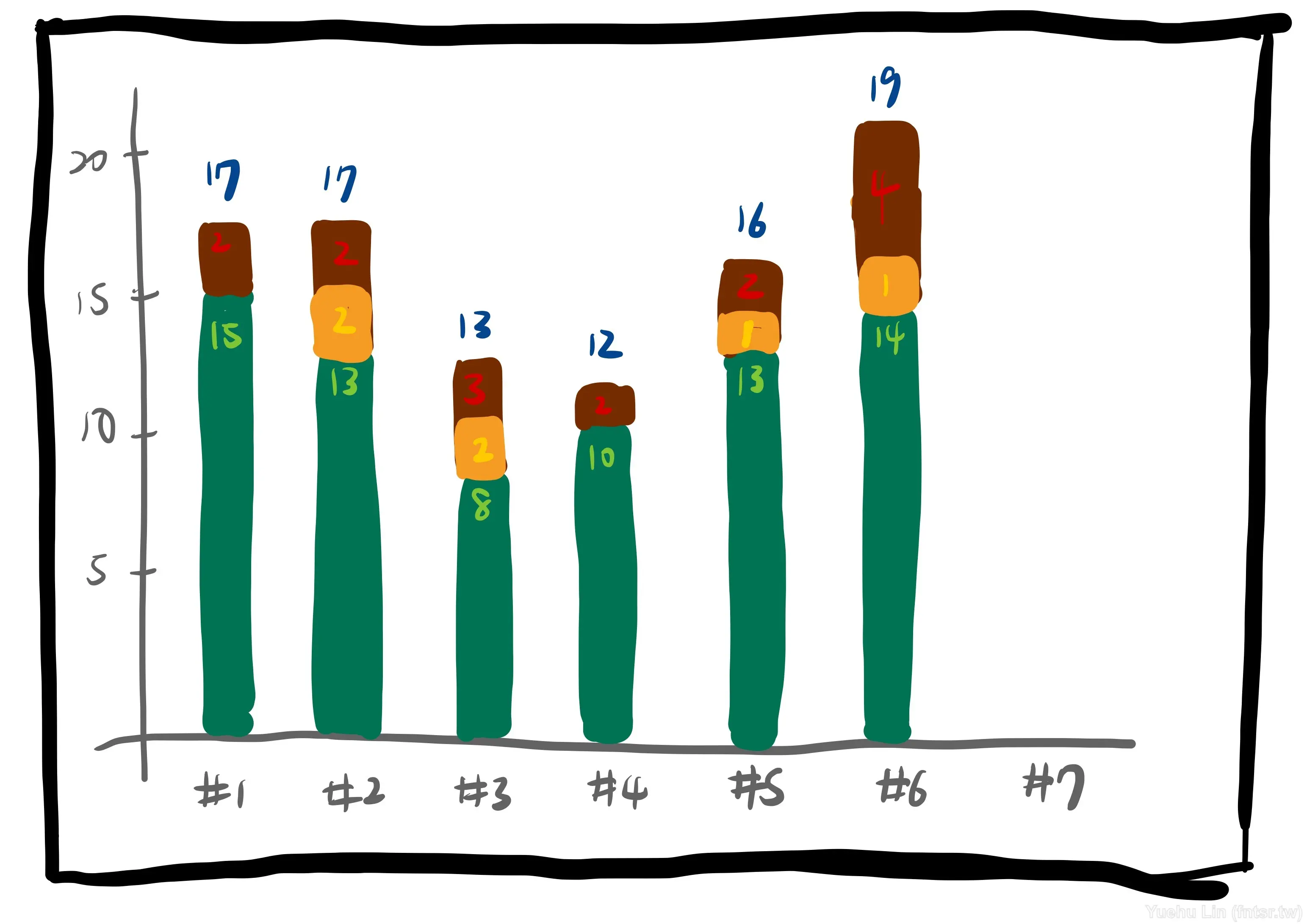
隨著頻繁出現產品待辦事項開始無法在一個 Sprint 完成,為了在下個 Sprint 能夠預測能拿多少工作量的準確度,團隊開始重新估算這些在製品。除此之外,也將原本的工作量扣除新估算出來的工作量,作為上週交付的的一部分。讓團隊能更貼近實際狀況的去了解自己上個 Sprint 交付的工作量。
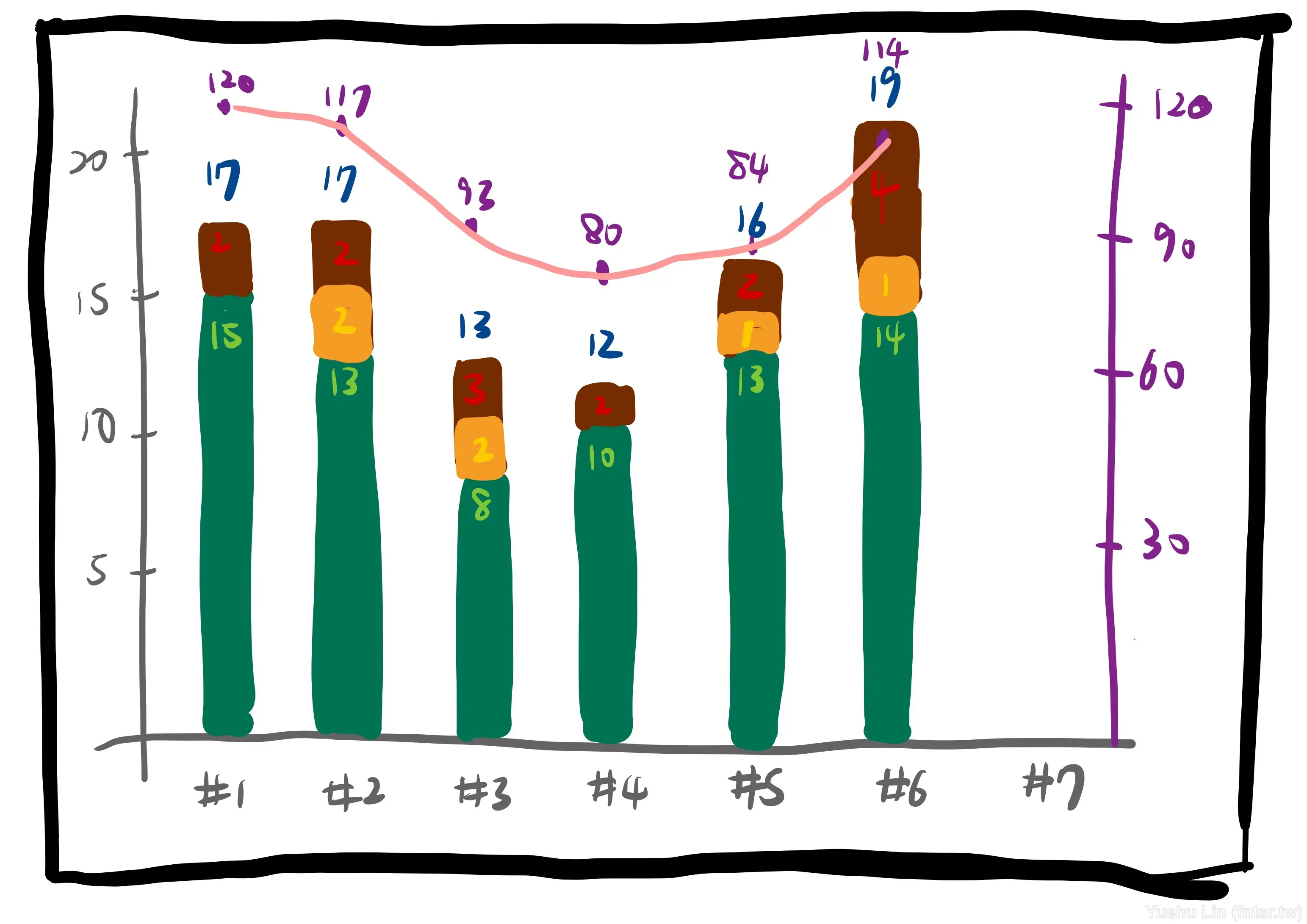
隨著團隊外務變多、或是長假頻繁、抑或是組成臨時變動,我們認為用過去人力充足的情況,去預測下個 Sprint 人力貧乏的工作量是不公平、不準確的。所以也開始計算了團隊能投入在產品開發的時間比例。
這部分的經驗就很有趣了,這樣的計算分成了多種計算方式:

在這個過程中,也會基於當時的人力單位,去計算每單位能完成的故事點,這些平均數個 Sprint 的平均每單位能完成故事點的數值乘上新 Sprint 能夠投入的人力,就可以得到這個 Sprint 預測能做到的工作量了。
演化的故事就大概就分享到這裡。不確定各位讀者看完這些演化過程的感想是什麼?是覺得能做到這種程度真的很完整、很厲害?還是覺得這套系統很方便,也想要來一套?或者覺得怎麼聽起來很是複雜,難以維護?
我想可能以上皆是吧!隨著需求,紀錄表開始往更細的方向開始去鑽,也就逐漸踏入了前幾天講到的陷阱。這些更細緻的計算方式,的確當時也為團隊帶來許多好處,滿足了各種需求。但其實這些特化的需求都代表著一些困境,只是我們嘗試最佳化目前的方案去解決,但這種方式就像是大家在產品發表會常講的俗語:「擠牙膏」,到最後總會有擠不出來的時候,屆時又該怎麼辦。
通常這時候記錄表的成本效益比就會越來越低,團隊也就會越來越沒動力填寫,最後停下來。我也有幸在這時候決斷地放下這個陪我們多年的實踐,嘗試使用另一個方式去滿足當初的需求,這就是後話了。
在這個演化中,得到了什麼好處,又是遇到了哪些困境讓我們掉入陷阱,最後停用呢?以及到底什麼情況適合使用速率表,細緻度又該怎麼權衡?篇幅有限,請待明日分享!

